

O1 vs. O3-mini: A Tale of 100 Live PRs
Recently, we ran a large-scale experiment to see how two AI models—O1 and O3-mini—would perform in real-world code reviews. We collected 100 live pull requests from various repositories, each containing a mix of Python, Go, Java, and asynchronous components. Our objective was to discover which model could catch the most impactful, real-world issues before they reached production.
TL;DR
Here's the surprising part: O3-mini not only flagged syntactic errors but also spotted more subtle bugs, from concurrency pitfalls to broken imports. Meanwhile, O1 mostly highlighted surface-level syntax problems, leaving deeper issues unaddressed. Below are six stand-out examples that show just how O3-mini outperformed O1—and why these catches truly matter.
We've grouped them into three major categories:
Performance
Maintainability & Organization
Functional Correctness & Data Handling
Let's dive in.
Category 1: Performance
Offloading a Blocking Call in an Async Endpoint
During our review of an asynchronous service, O3-mini flagged a piece of code that appeared to block the event loop. O1 did not mention it at all.

Why It's a Good Catch by O3-mini
O1 ignored the potential for event-loop blocking.
O3-mini understood that in an async context, a CPU- or I/O-bound call can stall other coroutines, harming performance.
Category 2: Maintainability & Organization
Incorrect Import Paths for Nancy Go Functions
We discovered that certain Go-related functions for "Nancy" scanning had been imported from a Swift directory. O1 missed the mismatch entirely.
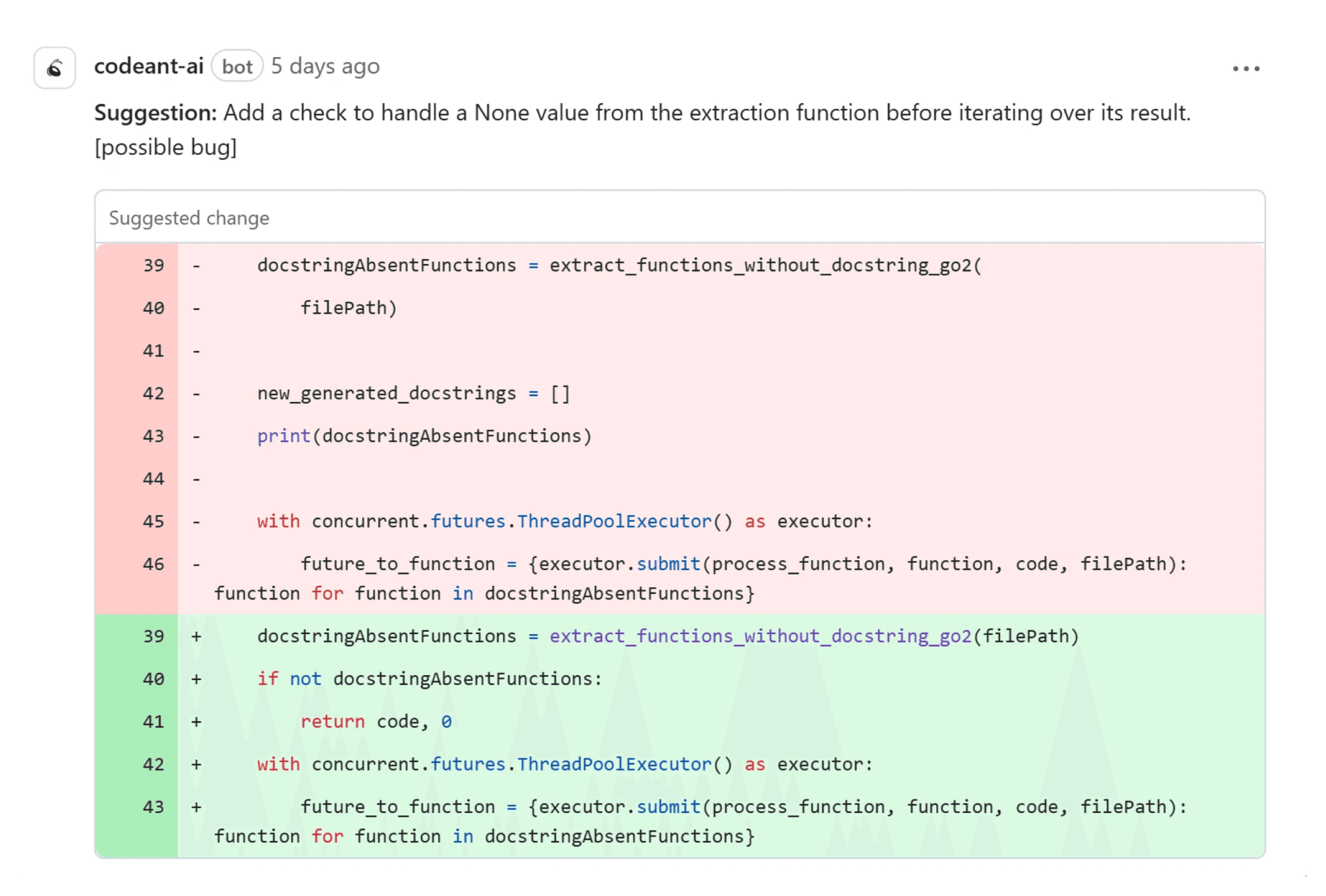
Why It's a Good Catch by O3-mini
O1 saw no syntax error, so it stayed quiet.
O3-mini recognized the semantic mismatch between "Swift" and "Go," preventing
ModuleNotFoundErrorat runtime.
Verifying Language-Specific Imports Match Their Actual Directories
In a similar vein, a Go docstring was being imported from a Java directory. Again, O1 overlooked it, while O3-mini raised a red flag.

Why It's a Good Catch by O3-mini
O1 didn't see any direct conflict in Python syntax.
O3-mini noticed that a "Go" function shouldn't be in a "Java" directory, which would cause confusion and possibly missing-module errors.
Category 3: Functional Correctness & Data Handling
Fragile String Splits vs. Robust Regular Expressions
In analyzing user reaction counts (👍 or 👎) in a GitHub comment, O3-mini recommended using a regex pattern instead of naive string-splitting. O1 missed this entirely.
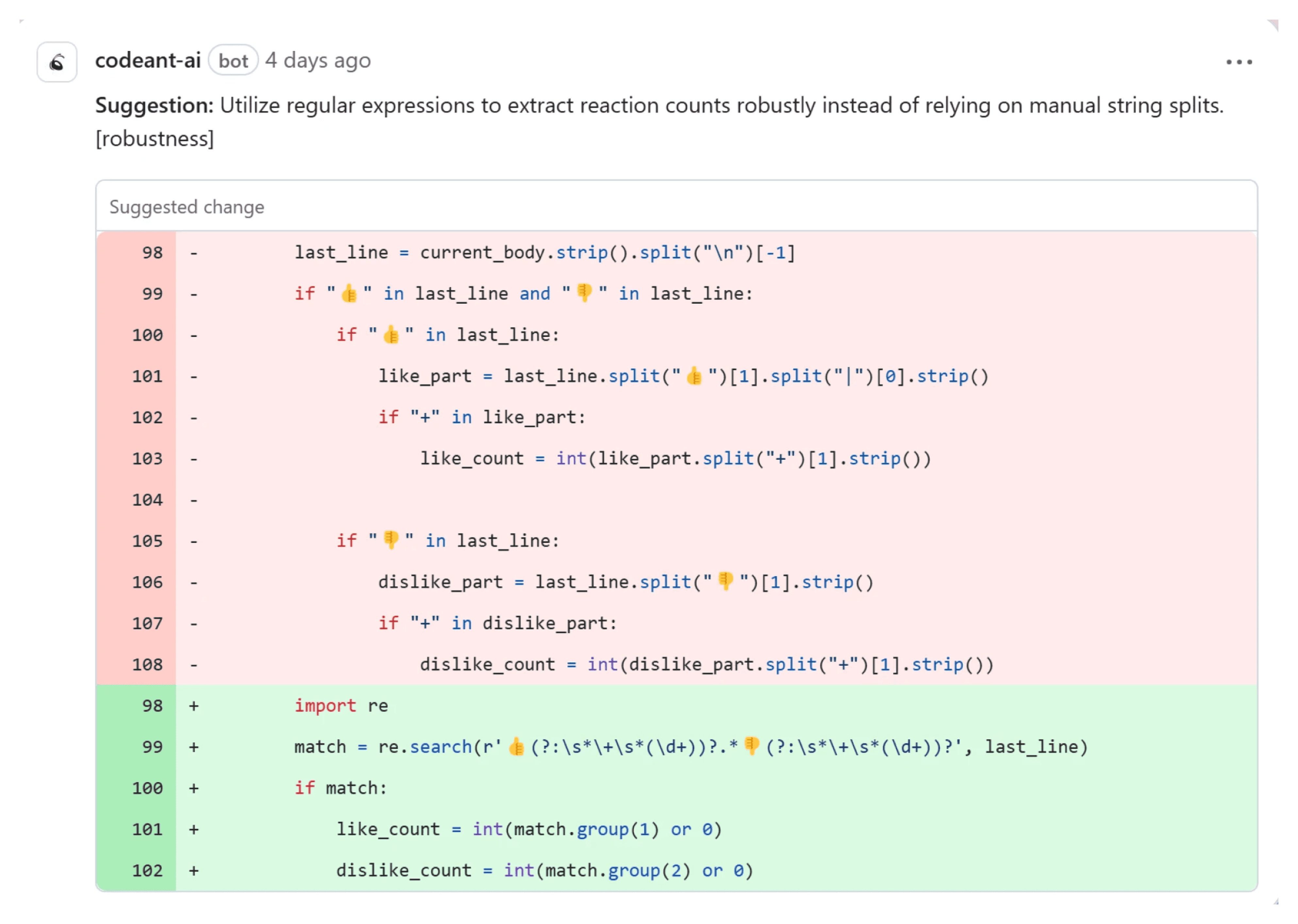
Why It's a Good Catch by O3-mini
O1 considered the code valid, not realizing format changes could break it.
O3-mini identified potential parsing failures if spacing or line structure changed, advocating a more robust regex solution.
Incorrect f-string interpolation for Azure DevOps
Here, the developer mistakenly used self.org as a literal string in an f-string. O1 allowed it to pass, but O3-mini flagged it as a logic error.

Why It's a Good Catch by O3-mini
O1 only checks basic syntax and saw no problem.
O3-mini noticed the URL was invalid due to a literal "self.org," causing 404s in a real Azure DevOps environment.
Using the Correct Length Reference in Analytics
Finally, O3-mini picked up on a subtle but important discrepancy in analytics code, where len(code_suggestion) was used instead of len(code_suggestions). O1 didn't detect this mismatch in logic.
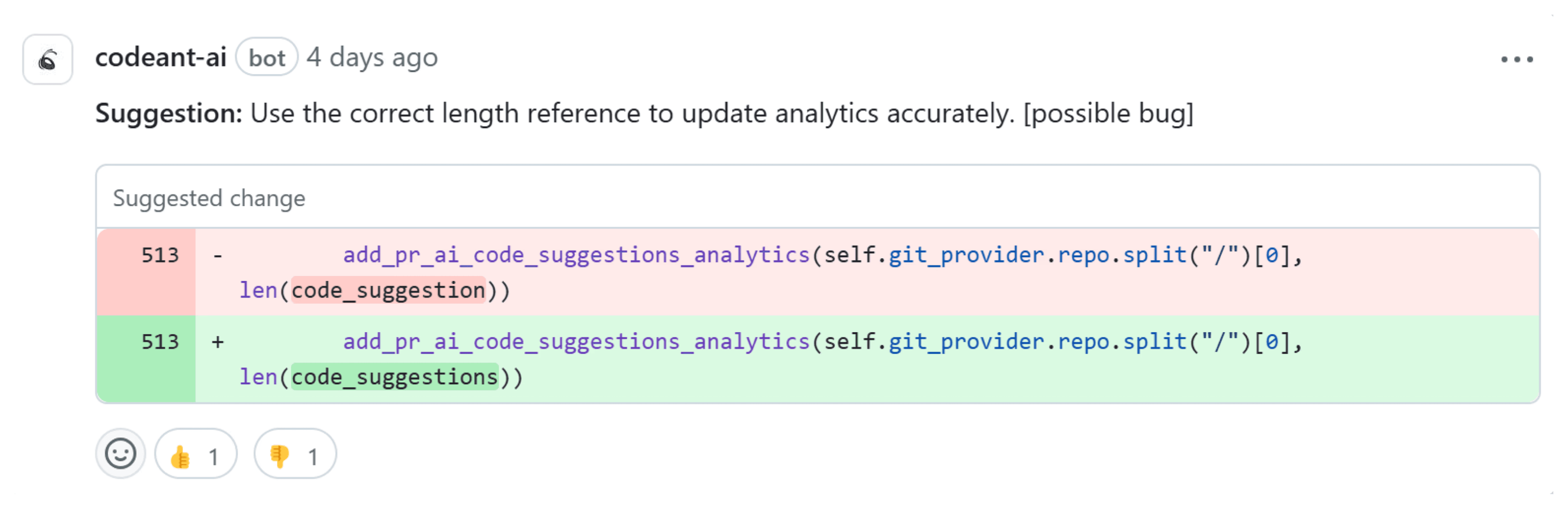
Why It's a Good Catch by O3-mini
O1 wasn't aware of the semantic context, so it didn't question the single "code_suggestion."
O3-mini understood the variable naming implied multiple suggestions, preventing misleading analytics data.
Final Conclusions: O3-mini vs. O1
In our experiment covering 100 live PRs, O3-mini flagged a total of 78 subtle issues that O1 missed entirely. Many of these issues, like the ones above, could have caused real headaches in production—ranging from performance bottlenecks to CI/CD pipelines and inaccurate analytics.
Here's a quick summary table of how these issues map to the three categories we discussed, and whether O1 or O3-mini flagged them correctly:
Category | Issue | O1 Missed? | O3-mini Flagged? | Real-World Impact |
|---|---|---|---|---|
Performance | Offloading blocking call ( | Yes | Yes | Prevents concurrency stalls in async apps |
Maintainability & Organization | Incorrect import paths (Nancy Go) | Yes | Yes | Avoids build errors, clarifies directory structure. |
Maintainability & Organization | Mismatched language-specific imports (Go from Java) | Yes | Yes | Stops confusion for new devs, prevents module errors. |
Functional Correctness & Data | Fragile string splits vs. regex for emojis | Yes | Yes | Prevents silent parser failures when formats change |
Functional Correctness & Data | Literal | Yes | Yes | Ensures valid endpoints, stops 404s. |
Functional Correctness & Data | Wrong length reference in analytics ( | Yes | Yes | Avoids misleading data and invalid product decisions. |
As you can see, O1 missed all six of these nuanced issues, focusing mostly on obvious syntax checks. O3-mini excelled at catching subtle logic and architectural pitfalls, demonstrating the value of deeper reasoning capabilities in AI code reviews.
Wrapping Up the Story
After analyzing 100 live PRs with both models, we can conclude that O3-mini isn't just better at "edge cases"—it's also a more consistent at spotting logical errors, organizational mismatches, and performance bottlenecks. Whether you're maintaining a large codebase or scaling up your microservices, an AI reviewer like O3-mini can act as a powerful safety net, preventing problems that are easy to overlook when you're juggling multiple languages, frameworks, and deployment pipelines.
Ultimately, the difference is clear: O1 might catch a misspelled variable name, but O3-mini catches the deeper issues that can save you from hours of debugging and production incidents.

